Retrieval augmented generation is one of the most popular applications of LLMs. It involves feeding the LLM with context that informs its generation, thus grounding the response in our custom data. Why would we want to do that? As good as LLMs are at language understanding, their knowledge is still frozen in time, in terms of their knowledge cutoff. So, when we need to supply the LLM with some external context, we use RAG.
Given a particular query, RAG works around the limited input token window size that an LLM has by only supplying relevant context.
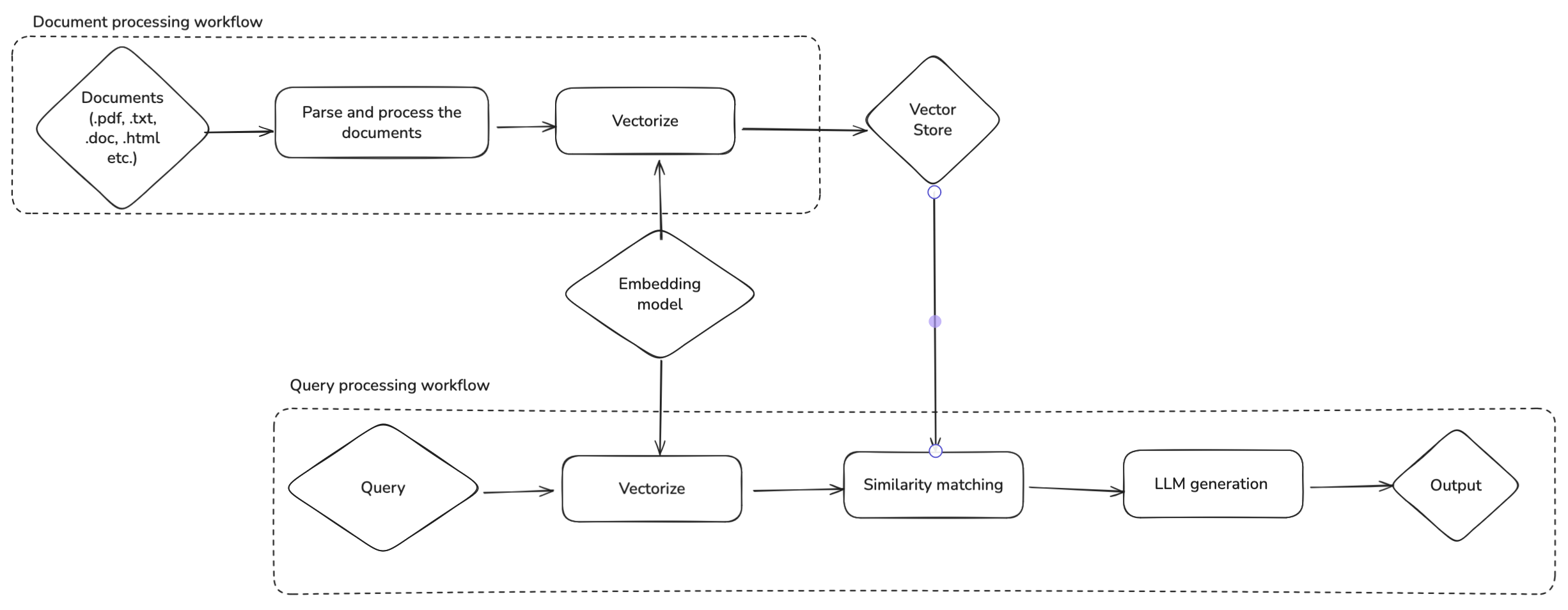
At a high level, a typical RAG workflow looks like the following:
Figure 1: RAG Workflow
In this notebook, we will implement a type of RAG pipeline which proves to be a very strong baseline among many known RAG methods, as observed in this research paper. It’s called Document Original Structure RAG (DOS-RAG). The core idea is that after similarity matching, the retrieved document chunks are ordered based on their original order in the document rather than sorting by chunk score.
Let’s get started!
2. Load the data
We will be using a chapter from a science textbook to demonstrate this technique. Let’s see what it looks like!
import pymupdf # PyMuPDFimport matplotlib.pyplot as pltfrom PIL import Imageimport io# Read the PDF filepdf_path ="../assets/dos-rag/atoms and molecules.pdf"doc = pymupdf.open(pdf_path)# Get the first pagefirst_page = doc[0]# Convert page to imagemat = first_page.get_pixmap(matrix=pymupdf.Matrix(2, 2)) # 2x zoom for better qualityimg_data = mat.tobytes("png")# Convert to PIL Image for displayimg = Image.open(io.BytesIO(img_data))# Get image dimensionswidth, height = img.size# Crop the top halftop_half = img.crop((0, 0, width, height //2))# Display the top halfplt.figure(figsize=(10, 6))# Display the imageplt.figure(figsize=(10, 12))plt.imshow(top_half)plt.axis("off")plt.show()# Close the documentdoc.close()
<Figure size 960x576 with 0 Axes>
We will be using lamaindex which is a popular framework to do all things related to RAG and more. We will first load the pdf into a datastructure called document and then split the given documents in chunks.We’ll use the SimpleDirectoryReader and TextSplitter utilities provided by LlamaIndex.
from llama_index.core import SimpleDirectoryReaderfrom llama_index.core.node_parser import SentenceSplitter# Load the PDF as a documentdocuments = SimpleDirectoryReader(input_files=[pdf_path]).load_data()# Let's inspect the first documentprint(f"Number of documents loaded: {len(documents)}")print("Preview of the first document:")print(documents[0].text[:500]) # Show the first 500 characters
Number of documents loaded: 12
Preview of the first document:
Ancient Indian and Greek philosophers have
always wonder ed about the unknown and
unseen form of matter. The idea of divisibility
of matter was considered long back in India,
around 500 BC. An Indian philosopher
Maharishi Kanad, postulated that if we go on
dividing matter (padarth), we shall get smaller
and smaller particles. Ultimately, a stage will
come when we shall come across the smallest
particles beyond which further division will
not be possible. He named these particles
Par manu . Anot
Now, let’s split the document into chunks. Chunking is important for efficient retrieval and to fit within the LLM’s context window. We are usingt the SentenceSplitter class that creates chunks (nodes) keeping in mind proper sentence boundary. Also note that the parameters of chunk_size and chunk_overlap are set this way for this demo.
# Split the document into nodessplitter = SentenceSplitter(chunk_size=512, chunk_overlap=128)nodes = splitter.get_nodes_from_documents(documents)print(f"Number of nodes created: {len(nodes)}")print("Preview of the first node:")print(nodes[0].text)
Number of nodes created: 22
Preview of the first node:
Ancient Indian and Greek philosophers have
always wonder ed about the unknown and
unseen form of matter. The idea of divisibility
of matter was considered long back in India,
around 500 BC. An Indian philosopher
Maharishi Kanad, postulated that if we go on
dividing matter (padarth), we shall get smaller
and smaller particles. Ultimately, a stage will
come when we shall come across the smallest
particles beyond which further division will
not be possible. He named these particles
Par manu . Another Indian philosopher ,
Pakudha Katyayama, elaborated this doctrine
and said that these particles nor mally exist
in a combined for m which gives us various
forms of matter.
Around the same era, ancient Gr eek
philosophers – Democritus and Leucippus
suggested that if we go on dividing matter, a
stage will come when particles obtained
cannot be divided further. Democritus called
these indivisible particles atoms (meaning
indivisible). All this was based on
philosophical considerations and not much
experimental work to validate these ideas
could be done till the eighteenth century.
By the end of the eighteenth century,
scientists r
ecognised the difference between
elements and compounds and naturally
became interested in finding out how and why
elements combine and what happens when
they combine.
Antoine L. Lavoisier laid the foundation
of chemical sciences by establishing two
important laws of chemical combination.
3.1 Laws of Chemical Combination
The following two laws of chemical
combination were established after
much experimentations by Lavoisier and
Joseph L. Proust.
3.1.1 LAW OF CONSERVATION OF MASS
Is there a change in mass when a chemical
change (chemical reaction) takes place?
Activity ______________ 3.1
• Take one of the following sets, X and Y
of chemicals—
X Y
(i) copper sulphate sodium carbonate
(ii) barium chloride sodium sulphate
(iii) lead nitrate sodium chloride
• Prepare separately a 5% solution of
any one pair of substances listed
under X and Y each in 10 mL in water.
For DOS-RAG to work we need the order information from the document e.g. page number and reading order. Let’s access metadata of node to observe what we have.
print("Node info: ", nodes[0].get_node_info())print("Metadata: ", nodes[0].get_metadata_str())# Let's add the start idx of the node to the metadata, it will be used to order the nodesfor node in nodes: node.metadata["start_idx"] = node.get_node_info()["start"]
We have the page number and reading order information in the metadata. We will use this information to order the chunks post similarity matching and retrieval.
3. Similarity matching and retrieval
We will be using the VectorStoreIndex class to create an index of the nodes. We will use the SimpleDirectoryReader to load the data and the SentenceSplitter to split the document into chunks. We are using the Gemini model from google to create embeddings.
As we can see, post processing the nodes sorts them based on the page number and reading order rather than the score, which is the core idea behind DOS-RAG. This simple post processing step is enough to setup a good baseline for a RAG application.
Summary
RAG is a powerful technique to improve the accuracy of LLM responses by providing it with relevant context.
DOS-RAG is a simple post processing step that can be used to order the retrieved nodes based on the page number and reading order.
We take a document and split it into chunks, create an index of the chunks and then retrieve the most relevant chunks based on the query.
Using simple sorting of the retrieved nodes based on the page number and reading order, we can achieve a good baseline for a RAG application.